Physical Address:
ChongQing,China.
WebSite:

Just Love Coding,Love Share And Writting



本博客内容属于个人原创,由于能力有限,难免存有错误,还请各位不吝指正。
如需转载,请注明出处。
对于很多C/C++开发人员而言,大小端这个词一定有所听闻。而其他语言的开发者,如JAVA、Python等上层语言开发者,则可能从未听说过这个词。
那么,什么是大小端呢。
大端模式:Big-endian,是指数据的高字节部分保存在内存的低地址处,而低字节部分则保存在内存的高地址处。
小端模式:Little-endian,是指数据的高字节部分保存在内存的高地址处,而低字节部分则保存在内存的低地址处。
如果只是简单描述这样一个概念,大家对大小端的理解也仅仅停留在概念上而已。那么,为什么会有大小端呢,在什么场合需要考虑到大小端呢。
现在假设我们需要向另一个进程传输一个数据,其值为0x720000。这时候我们一般会约定按照大端模式进行传递,这样当我们以字节数组传递时,形式是这样的:
unsigned char data[4]={0x72,0x00,0x00,0x00};此时data[0]=0x72,data[1]=0x00,data[2]=0x00,data[3]=0x00。这时候使用大端模式,其实是为了方便人类的阅读和书写,因为这样更符合人们从左往右的阅读习惯。
现在让我们来看看,0x7200000000这个数据在计算机内部是如何存储的。
如果是大端模式,那这个数据的存储格式是这样的:
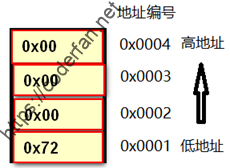
如果是小端模式,则其存储的格式为:
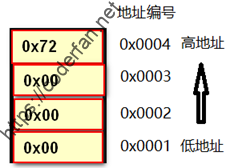
当CPU要对0x72000000这个数据进行计算处理时,由于涉及到进位运算,都会先从低字节的数据开始执行运算过程,再加上计算机的寻址方式是从低地址向高地址进行迁移。所以在以上两种方式中,唯有小端模式能够使CPU以最小的开销完成计算。
所以,当代计算机大都以小端模式为主。
综合以上,我们其实可以得出:
在实际使用中,大小端还有其他的影响,那就是涉及到位操作时。
比如,外部向我们传输一个字节的数据,该数据为0x14。该数据共有8bit,其中不同的位域代表着不同的涵义。参见以下代码:
union example
{
unsigned char data;
struct
{
unsigned char a:1;
unsigned char b:1;
unsigned char c:1;
unsigned char d:1;
unsigned char e:1;
unsigned char f:1;
unsigned char g:1;
unsigned char h:1;
}V;
};
union example Example.data=0x14;结合上文,现在我们已经知道共用体变量Example中的data数据为0x14,现在我们要分别求出Examlpe.V.a与 Examlpe.V.b…… Examlpe.V.h的值,如果是大端模式,其值为:
Example.V.a=0;
Example.V.b=0;
Example.V.c=0;
Example.V.d=1;
Example.V.e=0;
Example.V.f=1;
Example.V.g=0;
Example.V.h=0;如果是小端模式,其各自的值则为:
Example.V.a=0;
Example.V.b=0;
Example.V.c=1;
Example.V.d=0;
Example.V.e=1;
Example.V.f=0;
Example.V.g=0;
Example.V.h=0;为了便于大家更好的理解,我将其写成以下形式:

由此可以得出,大小端对单个字节的位域是有很大影响的,如果是大端模式,其位域排列由高bit指向低bit,即由bit7->bit0,而小端模式则相反。
再次对大小端做个总结:



